building a mini CMS from scratch for this website (lelu.uk)
update 2026-02-04: added image sizing and image row support
what’s the minimum viable static site generator?
This site runs on a custom static site generator built in python. It’s about 400 lines of code total, generates this entire website, and took a couple of evenings to build. This explainer is actually generated by the generator itself :)
I’ve done my research though, and there are plenty of options I know, like Hugo TinaCMS or loads of others. But I wanted something I could understand completely, modify easily, and that does exactly what I need, nothing more.
The philosophy is simple:
No frontend frameworks: vanilla HTML, CSS, and JavaScript
Python: because it’s what I know
Markdown: because it’s easy to edit
Features on demand: only what’s actually needed
Let’s walk through how it works.
content features
The CMS supports a handful of features that cover most of what I need for technical writing. Each feature is designed to have a clean markdown syntax that converts to semantic HTML.
frontmatter
Every article starts with YAML frontmatter that defines metadata:
---slug:my-articletitle:My Article Titledate:2026-01-05type:projectdescription:A short description for SEOdraft:false---
This populates the page title, meta tags, URL path, and the listing on the home page. The type field (project or post) determines which section it appears in.
The draft field is actually useful to work on something when I don’t want it to be picked up by the static generation yet.
images with captions
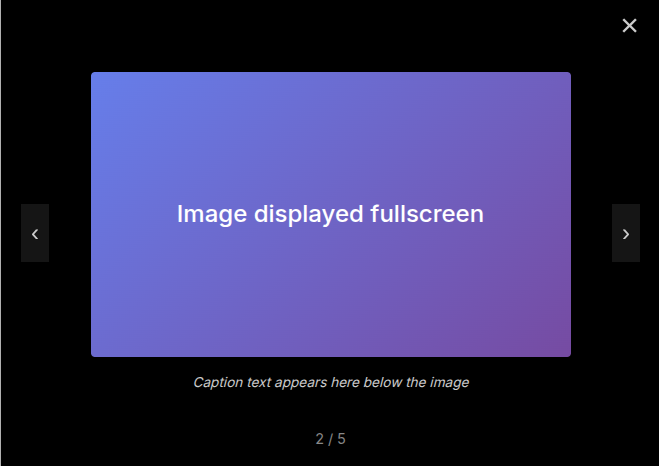
Standard markdown images can have captions by adding an italic line immediately after:

*The main interface showing all controls*
This renders as a semantic <figure> element with <figcaption>:
A figure with caption as rendered by the CMS
image sizing
Control image dimensions by adding {WIDTH} or {WIDTHxHEIGHT} after the image path:
The build runs in about 0.5 seconds for the entire site.
code walkthrough
markdown parser
The parser handles three main tasks: extracting frontmatter, converting markdown to HTML, and post-processing for custom features.
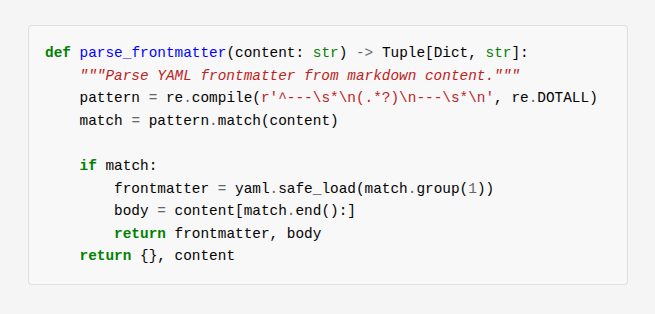
Frontmatter extraction uses a simple regex to find YAML between --- delimiters:
defparse_frontmatter(content:str)->Tuple[Dict[str,Any],str]:"""Parse YAML frontmatter from markdown content."""frontmatter_pattern=re.compile(r'^---\s*\n(.*?)\n---\s*\n',re.DOTALL)match=frontmatter_pattern.match(content)ifmatch:frontmatter_raw=match.group(1)body=content[match.end():]frontmatter=yaml.safe_load(frontmatter_raw)or{}else:frontmatter={}body=contentreturnfrontmatter,body
Image captions are detected after markdown conversion by looking for <img> followed by <em>:
defconvert_image_captions(html:str,base_path:str="")->str:"""Convert image + italic pattern to figure with figcaption."""# Pattern: <p><img ...>\n<em>caption</em></p>pattern=re.compile(r'<p>\s*<img\s+([^>]*?)\s*/?>\s*\n?\s*<em>([^<]+)</em>\s*</p>',re.IGNORECASE)defreplace_with_figure(match):img_attrs=match.group(1)caption=match.group(2)returnf'<figure>\n <img {img_attrs}>\n <figcaption>{caption}</figcaption>\n</figure>'returnpattern.sub(replace_with_figure,html)
Collapsible code blocks require preprocessing because the standard markdown parser doesn’t understand the collapsed keyword. We extract them before conversion, replace with placeholders, then restore them with proper <details> HTML after:
defpreprocess_collapsible_code(markdown_text:str)->tuple:"""Extract collapsed code blocks before markdown conversion."""pattern=re.compile(r'```(\w+)\s+collapsed\s+(.+?)\n(.*?)```',re.DOTALL)placeholders={}counter=[0]defreplace_with_placeholder(match):language=match.group(1)title=match.group(2).strip()code=match.group(3).rstrip()placeholder_id=f"COLLAPSEDCODEPLACEHOLDER{counter[0]}END"counter[0]+=1placeholders[placeholder_id]={'language':language,'title':title,'code':code}returnplaceholder_idprocessed=pattern.sub(replace_with_placeholder,markdown_text)returnprocessed,placeholders
template system (jinja2)
The template system is a thin wrapper around Jinja2. Here’s what we use from Jinja2 directly:
Environment: core class that holds configuration
FileSystemLoader: loads templates from disk
select_autoescape: prevents XSS by escaping HTML
Template inheritance: {% extends "base.html" %}
Blocks: {% block content %}{% endblock %}
Variables: {{ title }}, {{ content | safe }}
Loops & conditionals: {% for item in items %}, {% if condition %}
The wrapper just initializes Jinja2 with our preferences:
classTemplateEngine:"""Jinja2-based template engine for rendering HTML pages."""def__init__(self,templates_dir:Path):self.env=Environment(loader=FileSystemLoader(str(templates_dir)),autoescape=select_autoescape(['html','xml']),trim_blocks=True,# Remove newline after block tagslstrip_blocks=True# Strip whitespace before block tags)defrender(self,template_name:str,context:Dict[str,Any])->str:"""Render a template with the given context."""template=self.env.get_template(template_name)returntemplate.render(**context)
Template inheritance in practice:
base.html defines the page skeleton:
<!DOCTYPE html><htmllang="en"><head><title>{% block title %}{{ title }} - lelu.uk{% endblock %}</title><linkrel="stylesheet"href="/css/style.css"></head><body><divclass="container">
{% block content %}{% endblock %}
</div><scriptsrc="/js/main.js"></script></body></html>
article.html extends it and fills in the content block:
The entire generator is about 400 lines of python across three files. It builds this site in under a second, supports everything I need for technical writing, and I can extend it whenever I need something new.